


学术实证研究里,“数据分析” 往往是新手的 “卡壳重灾区”:拿到问卷数据不知道选什么方法、SPSS 操作半天出不了图表、结果和假设不符却找不到问题 —— 很多时候,不是研究思路有问题,而是 “数据处理的机械工作” 消耗了太多精力。
最近体验了 paperxie 智能写作中的「数据分析」功能,发现它刚好踩中了实证写作的核心痛点:把 “数据上传 - 方法选择 - 结果输出” 的流程压缩成 “三步操作”,同时保留学术分析的严谨性。今天就以实证研究的全流程为线索,拆解这个功能如何帮我们从 “数据堆” 快速搭建 “结论链”,同时聊聊学术数据分析工具的「合理使用边界」。
官网地址:点击直达
一、先「锚定分析目标」:研究信息填写是 “精准分析” 的前提
数据分析的第一步,从来不是 “上传数据”,而是 “明确你想通过数据回答什么问题”——paperxie 的「研究信息填写」环节,其实是在帮我们理清分析的核心目标。
这个环节的三个核心输入项,刚好对应实证研究的逻辑:
- 研究目的和问题:比如输入 “探究数字普惠金融对农村居民消费的影响机制”,系统会自动匹配 “变量关系分析” 的分析方向,避免后续方法选择偏离主题;
- 变量信息:需填写核心变量(如 “核心解释变量:数字普惠金融指数;被解释变量:农村居民人均消费支出”),这一步是在帮我们明确 “分析的核心对象”,避免数据维度混乱;
- 探索性分析结果:如果已经做了描述性统计(比如 “样本中农村居民月消费均值为 1200 元”),可以在此补充,系统会将其作为后续分析的 “基础参照”。
这里的细节很实用:系统会在输入框下方标注 “示例”(如 “描述性统计分析如集中趋势、离散程度等”),新手也能快速明确填写方向,避免 “不知道写什么” 的尴尬。
二、数据上传:「轻量化规范」降低操作门槛
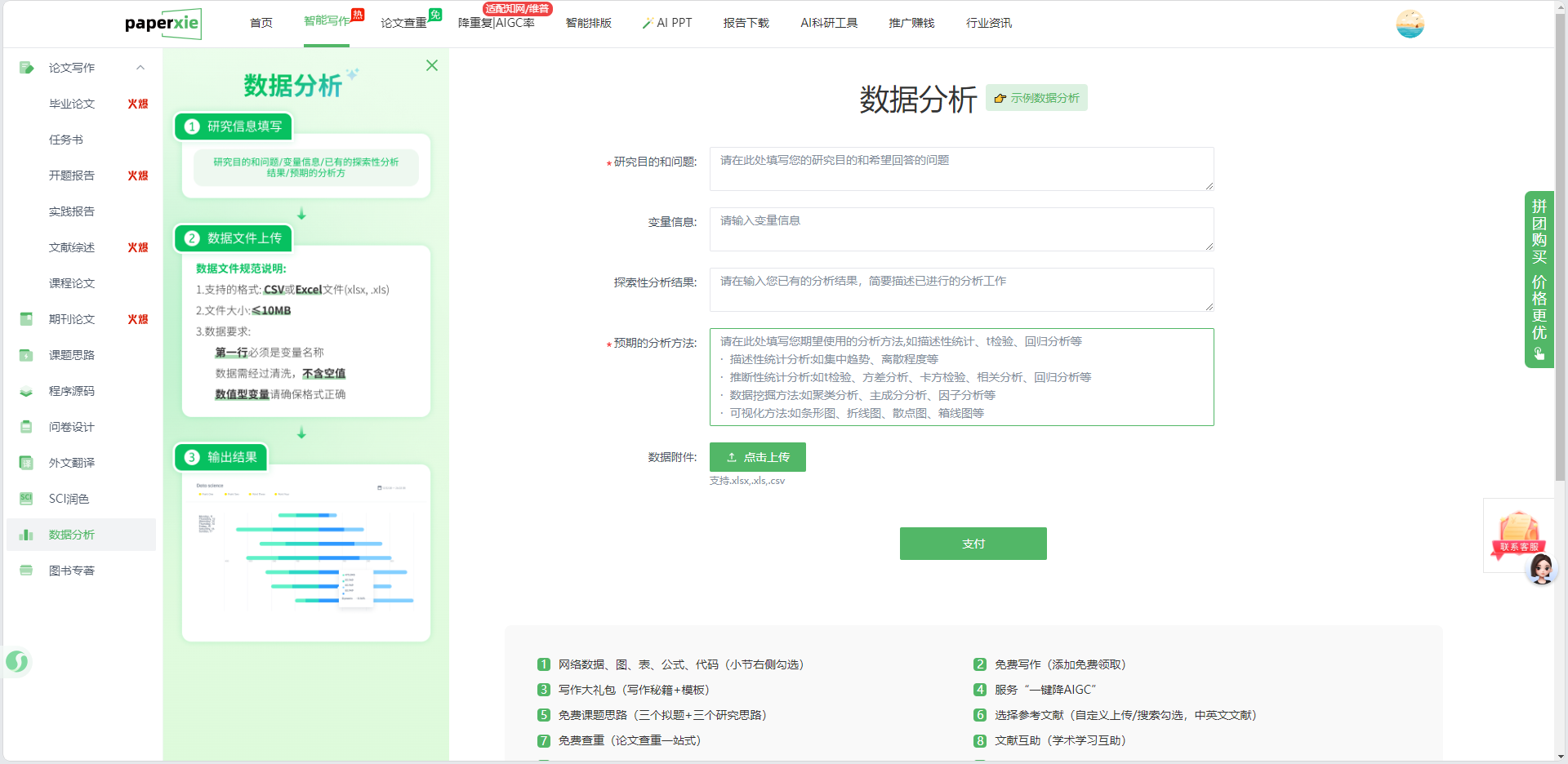
实证分析的 “第一道坎”,往往是 “数据格式不规范”—— 比如 Excel 里混有文本和数值、存在空值、变量名称不清晰,导致后续分析报错。
paperxie 的「数据文件上传」环节,用 “3 条规范 + 1 条提示” 直接解决这个问题:
- 支持格式:仅需上传 CSV 或 Excel 文件(.xls、.xlsx),覆盖了学术研究中最常用的数据格式;
- 文件大小限制:≤10MB,足够容纳问卷数据、面板数据等常见实证数据集;
- 数据要求:第一行必须是变量名称,数据需清洗(不含空值),数值型变量格式正确 —— 这其实是在帮我们提前完成 “数据预处理” 的核心步骤,避免后续分析出现 “变量识别失败” 的问题。
如果是新手,甚至可以直接参考系统提供的 “数据文件规范说明”,按要求整理数据,省去了学习 SPSS、Stata 数据导入规则的时间。
三、方法选择:「按需匹配」避免 “方法误用”
实证研究中最常见的问题之一,是 “分析方法和研究问题不匹配”—— 比如用 t 检验分析多组变量关系、用回归分析处理非线性数据。
paperxie 的「预期的分析方法」环节,用 “分类列举 + 示例” 的方式,帮我们快速选对方法:
- 描述性统计分析:如集中趋势(均值、中位数)、离散程度(标准差、方差)、卡方检验等,适合 “初步呈现数据特征”;
- 推断性统计分析:如 t 检验、方差分析、相关分析、回归分析等,适合 “验证变量关系假设”;
- 数据挖掘方法:如聚类分析、主成分分析、因子分析等,适合 “降维或分类数据”;
- 可视化方法:如条形图、折线图、散点图、箱线图等,适合 “直观呈现结果”。
比如我们的案例研究 “数字普惠金融对农村消费的影响”,需选择 “回归分析”+“散点图(呈现变量相关性)”,系统会自动基于选择的方法,对上传的数据进行对应分析,避免了 “方法选错导致结果无效” 的风险。
四、输出结果:「图表 + 结论」直接对接论文写作
完成以上步骤后,系统会输出「数据分析结果」—— 这也是这个功能最核心的价值:它不是只输出冷冰冰的数字,而是直接生成 “可直接嵌入论文的图表 + 初步结论”。
以案例为例,系统会自动生成:
- 描述性统计表格:包含核心变量的均值、标准差、样本量,直接对应论文中的 “数据描述部分”;
- 回归分析结果表:标注系数、标准误、p 值,帮我们快速判断 “变量关系是否显著”;
- 可视化图表:如数字普惠金融指数与消费支出的散点图 + 拟合线,直观呈现变量的线性关系;
- 初步结论文字:如 “数字普惠金融指数每提升 1 单位,农村居民人均消费支出显著增加 23.5 元(p<0.05)”,可直接作为论文 “实证结果分析” 的素材。
这个过程相当于帮我们完成了 “数据分析 - 结果呈现” 的机械性工作,后续只需要基于输出的结果,补充 “结果的经济学 / 管理学解释”“与现有研究的对比”,就能快速形成论文的实证部分。
五、工具的「合理使用边界」:它是 “辅助工具” 不是 “分析替身”
聊到学术数据分析工具,必须明确:paperxie 的数据分析功能,是 “提升效率的辅助工具”,而非 “替代研究者分析的替身”。
合理的使用方式应该是:
- 用工具完成 “机械性操作”:比如数据格式校准、基础统计分析、图表生成,节省时间;
- 自主判断 “结果的合理性”:比如系统输出回归结果后,需自主检查 “多重共线性”“异方差” 等问题,避免工具无法识别的模型缺陷;
- 自主补充 “结果的学术解释”:工具只能输出 “数据结论”,但论文需要的是 “基于结论的学术讨论”—— 比如 “数字普惠金融促进消费的机制,可能是通过降低信贷约束实现的”,这部分必须基于研究者的领域认知完成。
毕竟,实证研究的核心是 “通过数据验证研究假设”,工具可以帮我们处理数据,但不能替代我们对研究问题的理解和对结果的解读。
六、对比传统工具:paperxie 的「轻量优势」
和 SPSS、Stata 等专业统计软件相比,paperxie 的数据分析功能,优势在于 “轻量、低门槛”:
- 无需安装软件,网页端直接操作,适合电脑性能有限的学生;
- 无需学习复杂的代码或操作步骤,仅需填写信息、上传数据,新手也能快速上手;
- 输出结果直接对接论文写作,省去了 “将统计结果转化为论文内容” 的二次整理时间。
当然,它的局限性也很明显:无法处理复杂的面板数据模型、空间计量模型等高级分析方法 —— 这类复杂分析,仍需借助专业统计软件完成。但对于本科、硕士阶段的基础实证研究,paperxie 的功能已经足够覆盖需求。
写在最后:工具的本质是 “让研究者回归思考”
学术研究的核心,从来不是 “会不会操作软件”,而是 “能不能通过数据回答研究问题”。paperxie 的数据分析功能,刚好帮我们把 “数据处理的体力活” 剥离出去,让我们能把精力放在 “研究假设的设计”“结果的学术解释”“研究贡献的提炼” 这些真正体现研究价值的环节上。
工具是 “武器”,但研究者的 “思考” 才是 “武器的灵魂”—— 合理使用工具,才能让学术写作从 “痛苦的机械劳动” 变成 “专注的创造性工作”。

